
 与更为传统的基于规则的方案相比,它在吸纳了众多高手对局之后就具备了用梯度下降法自动调参的能力,所以性能提高起来会更快更省心。AlphaGo用这个办法达到了2微秒的走子速度和24.2%的走子准确率。24.2%的意思是说它的最好预测和围棋高手的下子有0.242的概率是重合的,相比之下,走棋网络在GPU上用2毫秒能达到57%的准确率。这里,我们就看到了走子速度和精度的权衡。 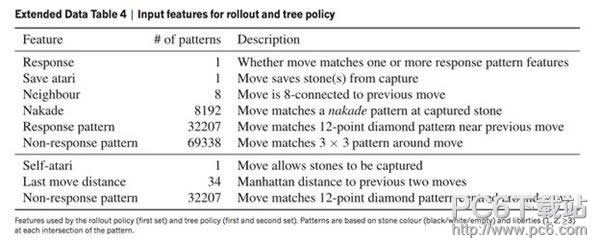 和训练深度学习模型不同,快速走子用到了局部特征匹配,自然需要一些围棋的领域知识来选择局部特征。对此AlphaGo只提供了局部特征的数目(见Extended Table 4),而没有说明特征的具体细节。我最近也实验了他们的办法,达到了25.1%的准确率和4-5微秒的走子速度,然而全系统整合下来并没有复现他们的水平。 我感觉上24.2%并不能完全概括他们快速走子的棋力,因为只要走错关键的一步,局面判断就完全错误了;而图2(b)更能体现他们快速走子对盘面形势估计的精确度,要能达到他们图2(b)这样的水准,比简单地匹配24.2%要做更多的工作,而他们并未在文章中强调这一点。 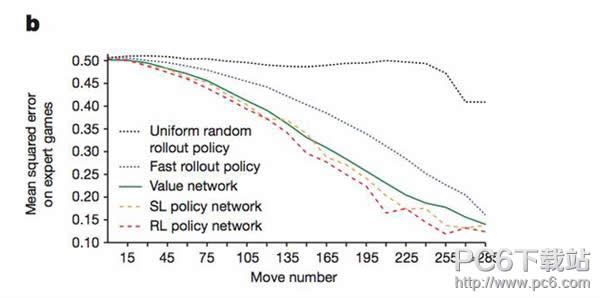 在AlphaGo有了快速走子之后,不需要走棋网络和估值网络,不借助任何深度学习和GPU的帮助,不使用增强学习,在单机上就已经达到了3d的水平(见Extended Table 7倒数第二行),这是相当厉害的了。任何使用传统方法在单机上达到这个水平的围棋程序,都需要花费数年的时间。在AlphaGo之前,Aja Huang曾经自己写过非常不错的围棋程序,在这方面相信是有很多的积累的。 3、估值网络 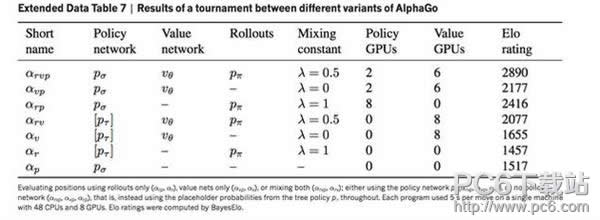 AlphaGo的估值网络可以说是锦上添花的部分,从Fig 2(b)和Extended Table 7来看,没有它AlphaGo也不会变得太弱,至少还是会在7d-8d的水平。少了估值网络,等级分少了480分,但是少了走棋网络,等级分就会少掉800至1000分。特别有意思的是,如果只用估值网络来评估局面(2177),那其效果还不及只用快速走子(2416),只有将两个合起来才有更大的提高。 我的猜测是,估值网络和快速走子对盘面估计是互补的,在棋局一开始时,大家下得比较和气,估值网络会比较重要;但在有复杂的死活或是对杀时,通过快速走子来估计盘面就变得更重要了。考虑到估值网络是整个系统中最难训练的部分(需要三千万局自我对局),我猜测它是最晚做出来并且最有可能能进一步提高的。 关于估值网络训练数据的生成,值得注意的是文章中的附录小字部分。与走棋网络不同,每一盘棋只取一个样本来训练以避免过拟合,不然对同一对局而言输入稍有不同而输出都相同,对训练是非常不利的。这就是为什么需要三千万局,而非三千万个盘面的原因。对于每局自我对局,取样本是很有讲究的,先用SL network保证走棋的多样性,然后随机走子,取盘面,然后用更精确的RL network走到底以得到最正确的胜负估计。当然这样做的效果比用单一网络相比好多少,我不好说。 一个让我吃惊的地方是,他们完全没有做任何局部死活/对杀分析,纯粹是用暴力训练法训练出一个相当不错的估值网络。这在一定程度上说明深度卷积网络(DCNN)有自动将问题分解成子问题,并分别解决的能力。 另外,我猜测他们在取训练样本时,判定最终胜负用的是中国规则。所以说三月和李世石对局的时候也要求用中国规则,不然如果换成别的规则,就需要重新训练估值网络(虽然我估计结果差距不会太大)。至于为什么一开始就用的中国规则,我的猜测是编程非常方便(我在写DarkForest的时候也是这样觉得的)。 4、蒙特卡罗树搜索 这部分基本用的是传统方法,没有太多可以评论的,他们用的是带先验的UCT,即先考虑DCNN认为比较好的着法,然后等到每个着法探索次数多了,选择更相信探索得来的胜率值。而DarkForest则直接选了DCNN推荐的前3或是前5的着法进行搜索。我初步试验下来效果差不多,当然他们的办法更灵活些,在允许使用大量搜索次数的情况下,他们的办法可以找到一些DCNN认为不好但却对局面至关重要的着法。 一个有趣的地方是在每次搜索到叶子节点时,没有立即展开叶子节点,而是等到访问次数到达一定数目(40)才展开,这样避免产生太多的分支,分散搜索的注意力,也能节省GPU的宝贵资源,同时在展开时,对叶节点的盘面估值会更准确些。除此之外,他们也用了一些技巧,以在搜索一开始时,避免多个线程同时搜索一路变化,这部分我们在DarkForest中也注意到了,并且做了改进。 |