
 AlphaGo为什么这么厉害?最近AlphaGo的世纪大战引发关注,前三场比赛均战胜李世石,那么AlphaGo究竟厉害在哪里?内容来自Facebook人工智能研究员田渊栋,曾就职于Google X部门,本文是其在人机大战赛前发于知乎上的分析。  最近我仔细看了下AlphaGo在《自然》杂志上发表的文章,写一些分析给大家分享。 AlphaGo这个系统主要由几个部分组成: 走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。 快速走子(Fast rollout),目标和1一样,但在适当牺牲走棋质量的条件下,速度要比1快1000倍。 估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。 蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。 我们的DarkForest和AlphaGo同样是用4搭建的系统。DarkForest较AlphaGo而言,在训练时加强了1,而少了2和3,然后以开源软件Pachi的缺省策略 (default policy)部分替代了2的功能。以下介绍下各部分。 1、走棋网络 走棋网络把当前局面作为输入,预测/采样下一步的走棋。它的预测不只给出最强的一手,而是对棋盘上所有可能的下一着给一个分数。棋盘上有361个点,它就给出361个数,好招的分数比坏招要高。 DarkForest在这部分有创新,通过在训练时预测三步而非一步,提高了策略输出的质量,和他们在使用增强学习进行自我对局后得到的走棋网络(RL network)的效果相当。当然,他们并没有在最后的系统中使用增强学习后的网络,而是用了直接通过训练学习到的网络(SL network),理由是RL network输出的走棋缺乏变化,对搜索不利。 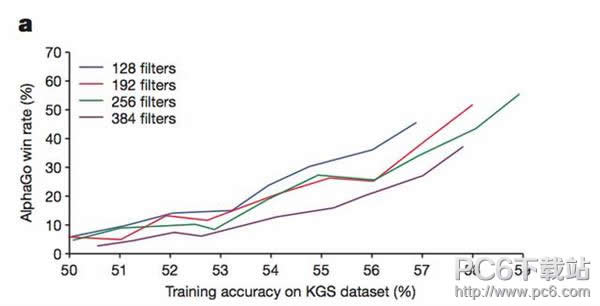 有意思的是在AlphaGo为了速度上的考虑,只用了宽度为192的网络,而并没有使用最好的宽度为384的网络(见图2(a)),所以要是GPU更快一点(或者更多一点),AlphaGo肯定是会变得更强的。 所谓的0.1秒走一步,就是纯粹用这样的网络,下出有最高置信度的合法着法。这种做法一点也没有做搜索,但是大局观非常强,不会陷入局部战斗中,说它建模了“棋感”一点也没有错。我们把DarkForest的走棋网络直接放上KGS就有3d的水平,让所有人都惊叹了下。 可以说,这一波围棋AI的突破,主要得益于走棋网络的突破。这个在以前是不可想像的,以前用的是基于规则,或者基于局部形状再加上简单线性分类器训练的走子生成法,需要慢慢调参数年,才有进步。 当然,只用走棋网络问题也很多,就我们在DarkForest上看到的来说,会不顾大小无谓争劫,会无谓脱先,不顾局部死活,对杀出错,等等。有点像高手不经认真思考的随手棋。因为走棋网络没有价值判断功能,只是凭“直觉”在下棋,只有在加了搜索之后,电脑才有价值判断的能力。 2、快速走子 那有了走棋网络,为什么还要做快速走子呢?有两个原因,首先走棋网络的运行速度是比较慢的,AlphaGo说是3毫秒,我们这里也差不多,而快速走子能做到几微秒级别,差了1000倍。所以在走棋网络没有返回的时候让CPU不闲着先搜索起来是很重要的,等到网络返回更好的着法后,再更新对应的着法信息。 其次,快速走子可以用来评估盘面。由于天文数字般的可能局面数,围棋的搜索是毫无希望走到底的,搜索到一定程度就要对现有局面做个估分。在没有估值网络的时候,不像国象可以通过算棋子的分数来对盘面做比较精确的估值,围棋盘面的估计得要通过模拟走子来进行,从当前盘面一路走到底,不考虑岔路地算出胜负,然后把胜负值作为当前盘面价值的一个估计。 这里有个需要权衡的地方:在同等时间下,模拟走子的质量高,单次估值精度高但走子速度慢;模拟走子速度快乃至使用随机走子,虽然单次估值精度低,但可以多模拟几次算平均值,效果未必不好。所以说,如果有一个质量高又速度快的走子策略,那对于棋力的提高是非常有帮助的。 为了达到这个目标,神经网络的模型就显得太慢,还是要用传统的局部特征匹配(local pattern matching)加线性回归(logistic regression)的方法,这办法虽然不新但非常好使,几乎所有的广告推荐,竞价排名,新闻排序,都是用的它。 |